Slice and Cluster Health Issues
Downed admission-webhook in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the admission-webhook component is down in a KubeSlice worker cluster. The admission-webhook plays a crucial role in validating and admitting new resources into the cluster. When admission-webhook becomes unavailable, it can impact resource validation and admission operations, leading to potential disruptions in the worker cluster. The solution below outlines steps to identify the worker cluster with a downed admission-webhook and verify its status to further investigate and resolve the root cause.
Root Cause
The admission-webhook may be down due to various reasons, such as errors during deployment, resource constraints,or configuration issues.
Impact
The impact of a downed admission-webhook includes:
-
Resource Validation Disruptions
With admission-webhook down, new resources may not be validated correctly, potentially leading to the creation of invalid or incompatible resources within the cluster.
-
Admission Failures
The unavailability of admission-webhook can prevent the admission of new resources into the cluster, causing delays in the deployment and management of applications.
Solution
To troubleshoot and resolve the issue of downed admission-webhook in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed admission-webhook
Use the following command to get the details of the admission-webhook deployment in the
kubeslice-systemnamespace:kubectl get deployment -n kubeslice-system --selector=app=admission-webhook-k8sExpected Output:
NAME READY UP-TO-DATE AVAILABLE AGE
nsm-admission-webhook-k8s 1/1 1 1 17d -
Verify admission-webhook Status on Worker Cluster
Get the status of the admission-webhook pod running in the
kubeslice-systemnamespace:kubectl get pods -n kubeslice-system --selector=app=admission-webhook-k8sExpected Output:
NAME READY STATUS RESTARTS AGE
nsm-admission-webhook-k8s-698784967d-nmtrl 1/1 Running 0 17dIf the STATUS is not Running, or if the number under READY is not 1/1, it indicates that the admission-webhook pod is down.
-
Investigate and Resolve the Root Cause
- Check the logs and events of the downed admission-webhook pod to identify the root cause of its unavailability.
- Investigate potential issues such as network connectivity problems, resource limitations, or admission-webhook configuration errors that may have caused admission-webhook to become down.
- Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the admission-webhook pod.
Conclusion
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed admission-webhook component in a KubeSlice worker cluster. Ensuring the availability of admission-webhook is essential for smooth resource validation and admission processes within the worker cluster. Swiftly addressing and resolving the root cause helps prevent potential resource validation disruptions and ensures a seamless flow of resource creation and management in the worker cluster.
Downed Egress in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the egress component is down in a KubeSlice worker cluster. The egress component plays a vital role in handling outgoing traffic and network egress operations. When egress becomes unavailable, it can disrupt outgoing network communication and impact the overall functionality of applications running in the worker cluster. The solution below outlines steps to identify the worker cluster with a downed egress and verify its status to further investigate and resolve the root cause.
Root Cause
The egress component may be down due to various reasons, such as errors during deployment, resource constraints, or configuration issues.
Impact
The impact of a downed egress includes:
-
Outgoing Traffic Disruptions
With egress down, outgoing network traffic from applications within the worker cluster may not be processed correctly, leading to potential communication failures with external services.
-
Network Egress Failures
The unavailability of egress can prevent applications from accessing external resources and services, potentially affecting the functionality and performance of the worker cluster.
Solution
To troubleshoot and resolve the issue of downed egress in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed Egress
Use the following command to get the details of the egress deployment in the
kubeslice-systemnamespace:kubectl get deployment -n kubeslice-system --selector=istio=egressgateway,slice=bookinfo-sliceExpected Output:
NAME READY UP-TO-DATE AVAILABLE AGE
bookinfo-slice-istio-egressgateway 1/1 1 1 17d -
Verify Egress Status on Worker Cluster
Get the status of the egress gateway pod running in the
kubeslice-systemnamespace:kubectl get pods -n kubeslice-system --selector=istio=egressgateway,slice=bookinfo-sliceExpected Output:
NAME READY STATUS RESTARTS AGE
bookinfo-slice-istio-egressgateway-7548b49659-9z4c5 2/2 Running 0 17dIf the STATUS is not Running," or if the number under READY is not 2/2, it indicates that the egress gateway pod is down.
-
Investigate and Resolve the Root Cause
- Check the logs and events of the downed egress gateway pod to identify the root cause of its unavailability.
- Investigate potential issues such as network connectivity problems, resource limitations, or egress configuration errors that may have caused egress to become down.
- Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the egress gateway pod.
Conclusion
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed egress component in a KubeSlice worker cluster. Ensuring the availability of egress is essential for handling outgoing network traffic and egress operations within the worker cluster. Swiftly addressing and resolving the root cause helps prevent potential disruptions to outgoing communication and ensures smooth access to external resources and services from applications running in the worker cluster.
Downed Forwarder in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the forwarder component is down in a KubeSlice worker cluster. Forwarder is a crucial component of the KubeSlice system responsible for forwarding kernel logs from worker nodes to the KubeSlice Controller. When forwarder encounters issues and becomes unavailable, it can disrupt kernel log forwarding, leading to potential log data loss and monitoring gaps. The solution below outlines steps to identify the worker cluster with a downed forwarder and verify its status to further investigate and resolve the root cause.
Root Cause
The forwarder component may be down due to various reasons, such as errors during deployment, resource constraints, or log forwarding issues.
Impact
The impact of a downed forwarder includes:
-
Kernel Log Data Loss
The unavailability of forwarder disrupts kernel log forwarding, resulting in potential data loss of critical log information.
-
Monitoring Gaps
Forwarder plays a crucial role in collecting and forwarding kernel logs for analysis. Its downtime can lead to monitoring gaps and hinder troubleshooting efforts.
Solution
To troubleshoot and resolve the issue of downed forwarder in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed Forwarder
Use the following command to get the details of the forwarder DaemonSet in the
kubeslice-systemnamespace:kubectl get daemonset -n kubeslice-system --selector=app=forwarder-kernelExpected Output:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
forwarder-kernel 3 3 3 3 3 <none> 17d -
Verify Forwarder Status on Worker Cluster
Get the status of all forwarder pods running in the
kubeslice-systemnamespace:kubectl get pods -n kubeslice-system --selector=app=forwarder-kernelExpected Output:
NAME READY STATUS RESTARTS AGE
forwarder-kernel-2zb9r 1/1 Running 0 17d
forwarder-kernel-jjzz7 1/1 Running 0 17d
forwarder-kernel-r5kcw 1/1 Running 0 17d
If any of the forwarder pods show a status other than "Running," it indicates that forwarder on that specific pod is down.
-
Investigate and Resolve the Root Cause
Check the logs and events of the downed forwarder pod to identify the root cause of its unavailability. Investigate potential issues such as connectivity problems, resource limitations, or log forwarding errors that may have caused forwarder to become down. Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the forwarder pod.
Conclusion
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed forwarder component in a KubeSlice worker cluster. Ensuring the availability of forwarder is crucial for continuous kernel log forwarding and maintaining complete log data for monitoring and analysis. Swiftly addressing and resolving the root cause helps prevent data loss and ensures seamless log forwarding within the KubeSlice environment.
Downed Ingress in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the ingress component is down in a KubeSlice worker cluster. The ingress component is responsible for handling incoming network traffic and routing it to the appropriate services within the worker cluster. When ingress becomes unavailable, it can lead to disruptions in the accessibility of applications and services from external sources. The solution below outlines steps to identify the worker cluster with a downed ingress and verify its status to further investigate and resolve the root cause.
Root Cause
The ingress component may be down due to various reasons, such as errors during deployment, resource constraints, or configuration issues.
Impact
The impact of a downed ingress includes:
-
Incoming Traffic Disruptions
With ingress down, incoming network traffic from external sources may not be correctly routed to the appropriate services within the worker cluster, leading to potential communication failures.
-
Service Accessibility Issues
The unavailability of ingress can prevent external sources from accessing services and applications hosted in the worker cluster, potentially affecting user experience and availability.
Solution
To troubleshoot and resolve the issue of downed ingress in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed Ingress
Use the following command to get the details of the ingress deployment in the
kubeslice-systemnamespace:kubectl get deployment -n kubeslice-system --selector=istio=ingressgateway,slice=bookinfo-sliceExpected Output:
NAME READY UP-TO-DATE AVAILABLE AGE
bookinfo-slice-istio-ingressgateway 1/1 1 1 17d -
Verify Ingress Status on Worker Cluster
Get the status of the ingress gateway pod running in the
kubeslice-systemnamespace:kubectl get pods -n kubeslice-system --selector=istio=ingressgateway,slice=bookinfo-sliceExpected Output:
NAME READY STATUS RESTARTS AGE
bookinfo-slice-istio-ingressgateway-765fb4ddf-d52cs 2/2 Running 0 17dIf the STATUS is not Running, or if the number under READY is not 2/2, it indicates that the ingress gateway pod is down.
-
Investigate and Resolve the Root Cause:
- Check the logs and events of the downed ingress gateway pod to identify the root cause of its unavailability.
- Investigate potential issues such as network connectivity problems, resource limitations, or ingress configuration errors that may have caused ingress to become down.
- Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the ingress gateway pod.
Conclusion
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed ingress component in a KubeSlice worker cluster. Ensuring the availability of ingress is essential for handling incoming network traffic and routing it to the appropriate services within the worker cluster. Swiftly addressing and resolving the root cause helps prevent potential disruptions to incoming communication and ensures smooth accessibility of services and applications hosted in the worker cluster from external sources.
Downed netop in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the netop component is down in a KubeSlice worker cluster. netop is a critical component responsible for managing network traffic operations in the KubeSlice environment. When netop becomes unavailable, it can disrupt network operations and impact the overall functionality of the KubeSlice system. The solution below outlines steps to identify the worker cluster with a downed netop and verify its status to further investigate and resolve the root cause.
Root Cause
The netop component may be down due to various reasons, such as errors during deployment, resource constraints, or network connectivity issues.
Impact
The impact of a downed netop includes:
-
Network Traffic Disruption
The unavailability of netop disrupts network traffic operations, leading to potential connectivity issues and service interruptions.
-
Loss of Network Control
netop plays a crucial role in managing network operations within the KubeSlice environment. Its downtime can lead to a lack of network control and hinder network management capabilities.
Solution
To troubleshoot and resolve the issue of downed netop in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed netop
Use the following command to get the details of the netop DaemonSet in the
kubeslice-systemnamespace:kubectl get daemonset -n kubeslice-system | grep kubeslice-netopExpected Output:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kubeslice-netop 2 2 2 2 2 <none> 17d -
Verify netop Status on Worker Cluster
Get the gateway nodes that run the netop pod:
kubectl get nodes --selector=kubeslice.io/node-type=gatewayExpected Output:
NAME STATUS ROLES AGE VERSION
gke-demo-cluster-2-s-demo-cluster-2-s-3e484d4b-cbnl Ready <none> 17d v1.23.16-gke.1400
gke-demo-cluster-2-s-demo-cluster-2-s-3e484d4b-qnwp Ready <none> 17d v1.23.16-gke.1400Get the status of all netop pods running in the
kubeslice-systemnamespace:kubectl get pods -n kubeslice-system --selector=app=app_net_opExpected Output:
NAME READY STATUS RESTARTS AGE
kubeslice-netop-dqsg7 1/1 Running 0 17d
kubeslice-netop-jc4c2 1/1 Running 0 11dIf any of the netop pods show a STATUS other than Running, it indicates that netop on that specific pod is down.
-
Investigate and Resolve the Root Cause
-
Check the logs and events of the downed netop pod to identify the root cause of its unavailability.
-
Investigate potential issues such as network connectivity problems, resource limitations, or network configuration errors that may have caused netop to become down.
-
Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the netop pod.
-
Conclusion:
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed netop component in a KubeSlice worker cluster. Ensuring the availability of netop is crucial for seamless network operations and maintaining control over network traffic within the KubeSlice environment. Swiftly addressing and resolving the root cause helps prevent network disruptions and ensures optimal network management within the KubeSlice system.
Downed nsmgr in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the nsmgr component is down in a KubeSlice worker cluster. nsmgr is a crucial component of the KubeSlice system responsible for managing network service instances in the kubeslice-system namespace. When nsmgr encounters issues and becomes unavailable, it can disrupt network service management and impact cluster operations. The solution below outlines steps to identify the worker cluster with a downed nsmgr and verify its status to further investigate and resolve the root cause.
Root Cause
The nsmgr component may be down due to various reasons, such as errors during deployment, connectivity issues, or resource constraints.
Impact
The impact of a downed nsmgr includes:
-
Network Service Disruption
The unavailability of nsmgr can lead to disruptions in managing network services within the worker cluster.
-
Resource Management Issues
nsmgr plays a crucial role in managing network resources efficiently. Its downtime can impact resource allocation and management.
Solution:
To troubleshoot and resolve the issue of downed nsmgr in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed nsmgr
Use the following command to get the details of the nsmgr DaemonSet in the
kubeslice-systemnamespace:kubectl get daemonset -n kubeslice-system --selector=app=nsmgrExpected Output
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
nsmgr 3 3 3 3 3 <none> 17d -
Verify nsmgr Status on Worker Cluster
Get the status of all nsmgr pods running in the
kubeslice-systemnamespace:kubectl get pods -n kubeslice-system --selector=app=nsmgrExpected Output
NAME READY STATUS RESTARTS AGE
nsmgr-6gfxz 2/2 Running 3 (40h ago) 17d
nsmgr-jtxxr 2/2 Running 2 (12d ago) 17d
nsmgr-tdmd8 2/2 Running 0 11dIf any of the
nsmgrpods show a STATUS other than Running, it indicates thatnsmgron that specific pod is down. -
Investigate and Resolve the Root Cause
-
Check the logs and events of the downed
nsmgrpod to identify the root cause of its unavailability. -
Investigate potential issues such as connectivity problems, resource limitations, or configuration errors that may have caused
nsmgrto become down. -
Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the
nsmgrpod.
-
Conclusion:
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed nsmgr component in a KubeSlice worker cluster. Ensuring the availability of nsmgr is crucial for smooth network service management and resource utilization within the cluster. Swiftly addressing and resolving the root cause helps maintain uninterrupted network service operations and ensures optimal performance in the KubeSlice environment.
Downed Slice Gateway in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the slice gateway
component (slicegateway) is down in a KubeSlice worker cluster. The slice gateway is responsible
for managing and routing traffic to services within the worker cluster. When the Slice Gateway becomes
unavailable, it can lead to disruptions in the accessibility of services and applications within the
worker cluster. The solution below outlines steps to identify the worker cluster with a downed Slice
Gateway and verify its status to further investigate and resolve the root cause.
Root Cause
The Slice Gateway (slicegateway) may be down due to various reasons, such as errors during
deployment, resource constraints, or configuration issues.
Impact
The impact of a downed Slice Gateway includes:
-
Service Accessibility Issues
With the Slice Gateway down, incoming traffic from external sources may not be correctly routed to the appropriate services within the worker cluster, leading to potential communication failures.
-
Ingress Disruptions
A downed Slice Gateway can disrupt the routing of incoming traffic from the ingress gateway to the services, resulting in service unavailability for external sources.
Solution
To troubleshoot and resolve the issue of a downed slice gateway in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed Slice Gateway
Use the following command to get the details of the slice gateway deployment in the
kubeslice-systemnamespace:kubectl get deployment -n kubeslice-system --selector=kubeslice.io/pod-type=slicegateway,kubeslice.io/slice=bookinfo-sliceExpected Output
NAME READY UP-TO-DATE AVAILABLE AGE
bookinfo-slice-worker-1-worker-2-0 1/1 1 1 17d
bookinfo-slice-worker-1-worker-2-1 1/1 1 1 17d -
Verify Slice Gateway Status on Worker Cluster: Get the status of the Slice Gateway pods running in the
kubeslice-systemnamespace:kubectl get pods -n kubeslice-system --selector=kubeslice.io/pod-type=slicegateway,kubeslice.io/slice=bookinfo-sliceExpected Output
NAME READY STATUS RESTARTS AGE
bookinfo-slice-worker-1-worker-2-0-97748d58b-sqm7s 3/3 Running 0 17d
bookinfo-slice-worker-1-worker-2-1-8496454697-mw8cs 3/3 Running 0 17dIf the STATUS is not Running, or if the number under READY is not 3/3, it indicates that one or more slice gateway pods are down.
-
Investigate and Resolve the Root Cause
-
Check the logs and events of the downed slice gateway pods to identify the root cause of their unavailability.
-
Investigate potential issues such as network connectivity problems, resource limitations, or Slice Gateway configuration errors that may have caused the slice gateway pods to become down.
-
Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the Slice Gateway pods.
-
Conclusion:
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed Slice Gateway in a KubeSlice worker cluster. Ensuring the availability of the Slice Gateway is crucial for managing and routing traffic to services within the worker cluster. Swiftly addressing and resolving the root cause helps prevent potential disruptions to service accessibility and ensures smooth routing of incoming traffic from the ingress gateway to the services within the worker cluster.
Downed spire-agent in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the spire-agent component is down in a KubeSlice worker cluster. spire-agent plays a crucial role in the security and identity management of the worker cluster. When spire-agent becomes unavailable, it can impact the security and identity- related operations within the cluster. The solution below outlines steps to identify the worker cluster with a downed spire-agent and verify its status to further investigate and resolve the root cause.
Root Cause
The spire-agent component may be down due to various reasons, such as errors during deployment, resource constraints, or network connectivity issues.
Impact
The impact of a downed spire-agent includes:
-
Security and Identity Risks
With spire-agent down, the worker cluster's security and identity management functionalities may be compromised, leading to potential security risks.
-
Authentication and Authorization Issues The unavailability of spire-agent can hinder authentication and authorization processes, leading to access control problems within the cluster.
Solution
To troubleshoot and resolve the issue of downed spire-agent in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed spire-agent
Use the following command to get the details of the spire-agent DaemonSet in the
spirenamespace:kubectl get daemonset -n spire --selector=app=spire-agentExpected Output
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
spire-agent 3 3 3 3 3 <none> 17d -
Verify spire-agent Status on Worker Cluster
Get the status of all spire-agent pods running in the
spirenamespace:kubectl get pods -n spire --selector=app=spire-agentExpected Output:
NAME READY STATUS RESTARTS AGE
spire-agent-l692m 1/1 Running 0 11d
spire-agent-nrfnf 1/1 Running 0 17d
spire-agent-xp5m8 1/1 Running 0 17dIf any of the spire-agent pods show a STATUS other than Running, it indicates that spire-agent on that specific pod is down.
-
Investigate and Resolve the Root Cause
-
Check the logs and events of the downed spire-agent pod to identify the root cause of its unavailability.
-
Investigate potential issues such as network connectivity problems, resource limitations, or spire-agent configuration errors that may have caused spire-agent to become down.
-
Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the spire-agent pod.
-
Conclusion
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed spire-agent component in a KubeSlice worker cluster. Ensuring the availability of spire-agent is crucial for maintaining a secure and well-organized worker cluster, especially with regards to security and identity management. Swiftly addressing and resolving the root cause helps prevent potential security risks and ensures smooth authentication and authorization processes within the worker cluster.
Downed spire-server in KubeSlice Worker Cluster
Introduction
This scenario provides guidance on troubleshooting and resolving the issue when the spire-server component is down in a KubeSlice worker cluster. spire-server is a critical component responsible for handling security and identity management in the cluster. When spire-server becomes unavailable, it can impact various security-related operations within the cluster. The solution below outlines steps to identify the worker cluster with a downed spire-server and verify its status to further investigate and resolve the root cause.
Root Cause
The spire-server component may be down due to various reasons, such as errors during deployment, resource constraints, or network connectivity issues.
Impact
The impact of a downed spire-server includes:
-
Security and Identity Risks
With spire-server down, the worker cluster's security and identity management functionalities may be compromised, leading to potential security risks.
-
Certificate Issuance and Validation Issues
The unavailability of spire-server can hinder the issuance and validation of certificates, affecting secure communication within the cluster.
Solution
To troubleshoot and resolve the issue of downed spire-server in a KubeSlice worker cluster, follow these steps:
-
Identify Worker Cluster with Downed spire-server
Use the following command to get the details of the spire-server
StatefulSetin thespirenamespace:kubectl get statefulset -n spire --selector=app=spire-serverExpected Output:
NAME READY AGE
spire-server 1/1 17d -
Verify spire-server Status on Worker Cluster
Get the status of the spire-server pod running in the
spirenamespace:kubectl get pods -n spire --selector=app=spire-serverExpected Output:
NAME READY STATUS RESTARTS AGE
spire-server-0 2/2 Running 0 17dIf the STATUS is not Running, or if the number under READY is not 2/2, it indicates that the spire-server pod is down.
-
Investigate and Resolve the Root Cause
- Check the logs and events of the downed spire-server pod to identify the root cause of its unavailability.
- Investigate potential issues such as network connectivity problems, resource limitations, or spire-server configuration errors that may have caused spire-server to become down.
- Address the identified issues based on the investigation, which may involve network adjustments, resource allocation changes, or restarting the spire-server pod.
Conclusion
By following the provided steps, administrators can troubleshoot and resolve the issue of a downed spire-server component in a KubeSlice worker cluster. Ensuring the availability of spire-server is crucial for maintaining a secure and well-organized worker cluster, especially with regards to security and certificate management. Swiftly addressing and resolving the root cause helps prevent potential security risks and ensures smooth certificate issuance and validation processes within the worker cluster.
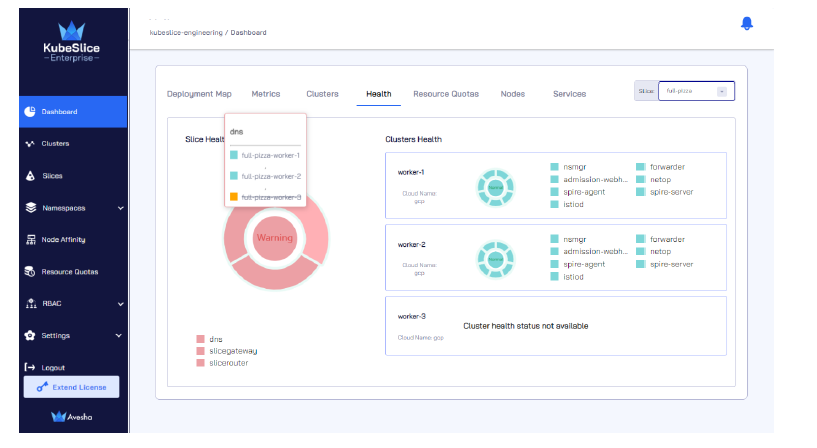
Unavailable Health Status for Worker Cluster in KubeSlice Manager Dashboard
Introduction
This scenario provides guidance on troubleshooting and resolving the issue where the KubeSlice
Manager dashboard's health tab displays the health status of a worker cluster as Unavailable. When a worker
cluster's health status is marked as unavailable, it indicates that the Worker Operator on that cluster is down or
experiencing communication issues with the KubeSlice Controller. The solution below outlines steps to identify and resolve the
root cause of this issue to ensure accurate health status representation in the KubeSlice Manager dashboard.
Root Cause
The unavailability of the worker cluster's health status in the KubeSlice Manager dashboard can be attributed to the Worker Operator being down or unable to communicate with the KubeSlice Controller.
Impact
The impact of the Unavailable health status includes:
-
Inaccurate Health Reporting
The KubeSlice Manager dashboard may display misleading health information for the affected worker cluster.
-
Limited Monitoring
The unavailability of health status can hinder monitoring and troubleshooting efforts for the worker cluster.
Solution
To resolve the issue of the worker cluster's health status showing as Unavailable in the KubeSlice Manager dashboard, follow these steps:
-
Check Worker Operator Status
a. Use the following command to get the details of the KubeSlice Worker Operator deployment in the
kubeslice-systemnamespace:kubectl get deployment -n kubeslice-system --selector=control-plane=controller-managerExpected Output
NAME READY UP-TO-DATE AVAILABLE AGE
kubeslice-operator 1/1 1 1 17db. Verify the status of KubeSlice Worker Operator pods in the
kubeslice-systemnamespace using the following command:kubectl get pods -n kubeslice-system --selector=control-plane=controller-managerExpected Output
NAME READY STATUS RESTARTS AGE
kubeslice-operator-789b475bb8-sz49v 2/2 Running 0 45h -
Restore Communication with KubeSlice Controller
a. If the KubeSlice Worker Operator pods are not running or have encountered errors, investigate the logs to identify the root cause of the communication issue. b. Ensure that the Worker Operator can communicate with the KubeSlice Controller by verifying network connectivity and ensuring there are no firewall restrictions. c. Restart the KubeSlice Worker Operator if necessary to restore communication with the KubeSlice Controller.
Conclusion
By following the provided steps, administrators can troubleshoot and resolve the issue of the worker cluster's health status being displayed as Unavailable in the KubeSlice Manager dashboard. Ensuring that the KubeSlice Worker Operator is running and able to communicate with the KubeSlice Controller is essential to obtain accurate health status information for the worker cluster. Addressing this issue promptly contributes to effective cluster monitoring and reliable health reporting in the KubeSlice environment.