Intelligent Application Scaling
Smart Scaler provides a solution to curb the escalating effort and expense associated with provisioning and managing scalable applications on Kubernetes clusters. It achieves this by leveraging AI and Reinforcement Learning models trained on system and application metrics data from the cluster. This eliminates the necessity for manual performance tuning of applications on production clusters to meet SLA requirements, as Smart Scaler conducts continuous tuning using production data.
Using Smart Scaler in scaling applications provides the following benefits:
- Smart Scaler scales proactively compared to normal HPA. It eliminates the need for manual tuning of HPA parameters each time a new release of software is deployed. Smart Scaler learns the application's requirements and automatically activates new resources as required.
- Smart Scaler learns the behavior of your application and the load patterns it experiences, dynamically growing or shrinking your deployment to meet demand and optimize costs.
- Smart Scaler also reports the relative performance patterns of your applications over time. This makes it easy to see when newer versions of code introduce changes in application performance and helps identify the microservices that are causing those changes.
- Smart Scaler achieves a higher utilization of available resources and can still spin up additional resources when required based on learned application behavior.
Overview
To effectively deploy complex micro-service based applications at scale in Kubernetes, it is necessary to utilize an auto-scaler such as Horizontal Pod Autoscaler (HPA) to manage scaling of microservices with varying load. However, the DevOps teams responsible for deploying and maintaining these applications need to tune the HPA parameters to ensure reliable services for the end users. This task becomes more challenging due to modern CI/CD pipelines constantly deploying new versions of the application with new varying performance characteristics, requiring frequent re-tuning of the HPA parameters. As a result, inefficiently utilized infrastructure and DevOps staff can lead to escalating costs.
Smart Scaler resolves this issue by preventing runaway costs in over-provisioned Kubernetes clusters using AI/Reinforcement Learning models trained on system and application metrics data for efficient resource allocation. This eliminates the need for manual performance tuning of production clusters to meet SLA requirements, as Smart Scaler performs continuous tuning of scaling metrics using production data. Smart Scaler agents can retrieve data from different metrics data sources for applications running in the Kubernetes clusters, with current support for Datadog and Prometheus.
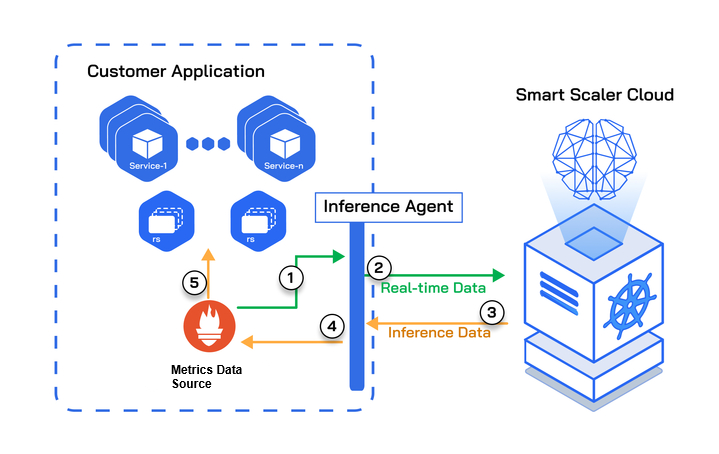
The following figure illustrates a customer application deployed on the Smart Scaler SaaS environment.
Ideal Scenarios
Smart Scaler is ideal for scenarios characterized by:
- Applications built from multiple microservices that are frequently evolving and that require frequent tuning from DevOps teams to scale and operate effectively
- Fluctuating traffic patterns, such as peak resource usage during typical work hours and minimal resource utilization during non-working hours
- Repeated workload patterns, such as batch processing, testing, or periodic data analysis
- Applications that experience significant delays during initialization, leading to noticeable latency issues when scaling out
Benefits
The benefit of Smart Scaler can be seen by applying learned application behavior to:
- Achieve higher utilization of available resources while still spinning up additional resources when required
- Eliminate the need for manual tuning of HPA parameters
- Reduce cloud costs
Smart Scaler Agent
The Smart Scaler Agent's main job is to collect real-time data from your systems. This data is then sent back to the Smart Scaler platform for the Inference stage of the Smart Scaler's Reinforcement Learning pipeline.
Inference is a process where the platform uses real-time data to make immediate decisions. In this case, it's used to calculate the exact number of pods of each microservice (making up your application) that need to be deployed to meet your Service Level Agreement (SLA). The SLA is a commitment between you and your users about the level of service they can expect.
The recommended pod counts from Smart Scaler are provided to the HPA component of Kubernetes. HPA is a feature in Kubernetes that automatically adjusts the number of pods in a deployment based on observed CPU utilization.
With Smart Scaler, you can see in real-time what the platform recommends in terms of pod deployment compared to application demand and your clusters' resource usage. This gives you a clear picture of how the platform is optimizing your resources.
To use Smart Scaler to manage your pod deployment, you need to change your HPA configuration to honor the Smart Scaler recommendations rather than produce its own. Of course, if for any reason you want to switch back to using vanilla HPA, you can easily do so through the configuration settings.