Overview
To effectively deploy a complex micro-service based applications at scale in Kubernetes, it is necessary to utilize an auto-scaler such as Horizontal Pod Autoscaler (HPA) to manage scaling of microservices with varying load. However, the DevOps teams responsible for deploying and maintaining these applications need to tune the HPA parameters to ensure reliable services for the end users. This task becomes more challenging due to modern CI/CD pipelines constantly deploying new versions of the application with new varying performance characteristics, requiring frequent re-tuning of the HPA parameters. As a result, inefficiently utilized infrastructure and DevOps staff can lead to escalating costs.
To address this issue, Smart Scaler offers a solution that prevents the runaway costs of heavily over-provisioned Kubernetes clusters by utilizing AI/Reinforcement Learning models trained on system and application metrics data from the cluster. This eliminates the need for manual performance tuning of production clusters to deliver on SLA, as Smart Scaler conducts continuous tuning using production data. Smart Scaler agents can retrieve metrics data from different data sources for applications running in the Kubernetes clusters. Smart Scaler supports all APM tools such as Prometheus, Datadog, AppDynamics, DynaTrace, New Relic, and other custom data sources.
The following figure illustrates a customer application deployed on the Smart Scaler SaaS environment.
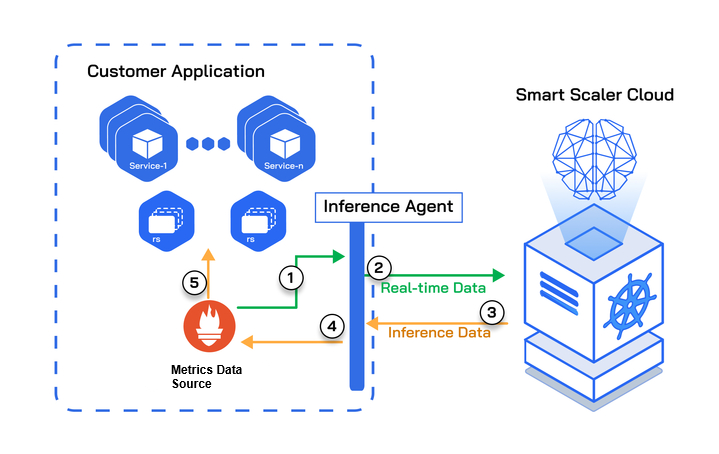
In the above topology diagram, the numbers reference the sequential steps for data traversal between the customer application and the SaaS cloud. The steps are described below:
- The Inference Agent configured on your cluster reads the real-time data from the metrics source.
- The Inference Agent then POSTs that data to the SaaS where the Smart Scaler inference logic will use that data to provide pod scale recommendations.
- Those recommendations are returned to the Inference Agent in response to its POST request. The agent then makes those recommendations available in its local metrics.
- The metrics source reads the Smart Scaler recommendations from the Inference Agent's metrics.
- The configured HPA reads the inference data from the metrics source and uses it to drive pod scaling for the configured applications.
Ideal Scenarios
Smart Scaler scales proactively compared with HPAs reactive behavior. Smart Scaler is ideal for scenarios characterized by:
- Fluctuating traffic patterns, such as peak resource usage during typical work hours and minimal resource utilization during non-working hours
- Repeated workload patterns, such as batch processing, testing, or periodic data analysis
- Applications that experience significant delays during initialization, leading to noticeable latency issues when scaling out
Benefits
The benefit of Smart Scaler can be seen by applying learned application behavior to:
- Achieve higher utilization of available resources while still spinning up additional resources when required
- Eliminate the need for manual tuning of HPA parameters
- Reduce cloud costs when compared to normal HPA