High-level Architecture
This topic illustrates the architecture diagrams of single cluster and multi-cluster deployments. It also provides an overview of the EGS Core APIs/SDK architecture for LLM use cases such as fine-tuning and inference.
EGS Controller is also referred to as KubeSlice Controller in some diagrams and documentation.
Multi-Cluster Deployment
The following figure shows the topology of the EGS multi-cluster deployment, including the controller cluster, worker clusters, and GPU node pools.
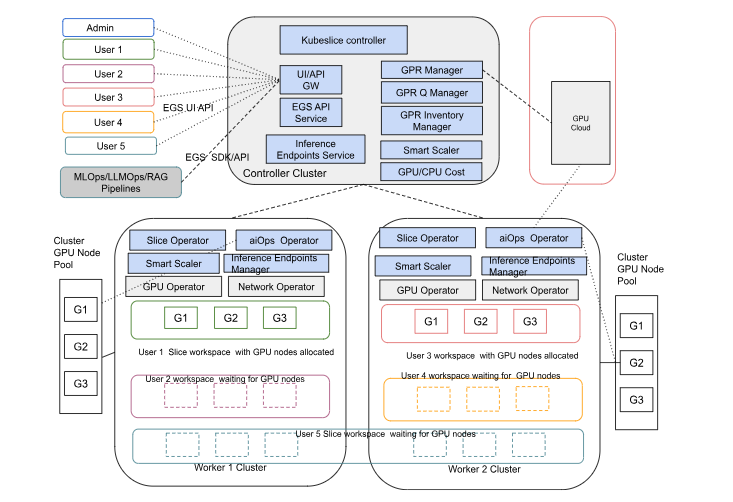
This architecture supports multi-cloud and hybrid deployments, allowing users to access GPU resources across different cloud providers and on-premises environments.
It includes the following components:
- Controller Cluster: Manages GPU allocation and provides APIs for users to access GPU resources
- Worker Clusters: Run user workloads in isolated workspaces, with GPU resources allocated from the controller cluster
- GPU Node Pools: Provide GPU capacity, which can be from local cluster pools or public/spot/on-demand pools
- Slice Operator: Manages user workspaces and ensures isolation
- GPU Operator: Allocates GPU resources to user workspaces
- Network Operator: Manages network resources for secure communication between workloads
- AI Ops Operator: Provides AI-driven operational insights and monitoring
- Workspace/Slice Overlay Network: Connects workloads across clusters, ensuring secure, low-latency communication
- Users: Access the platform through the EGS UI/API or automation pipelines, allowing for flexible and efficient GPU resource utilization
For more details, see EGS concepts.
Workspace Deployment using an Overlay Network
The following figure shows the topology of the EGS workspace deployment using an overlay network.
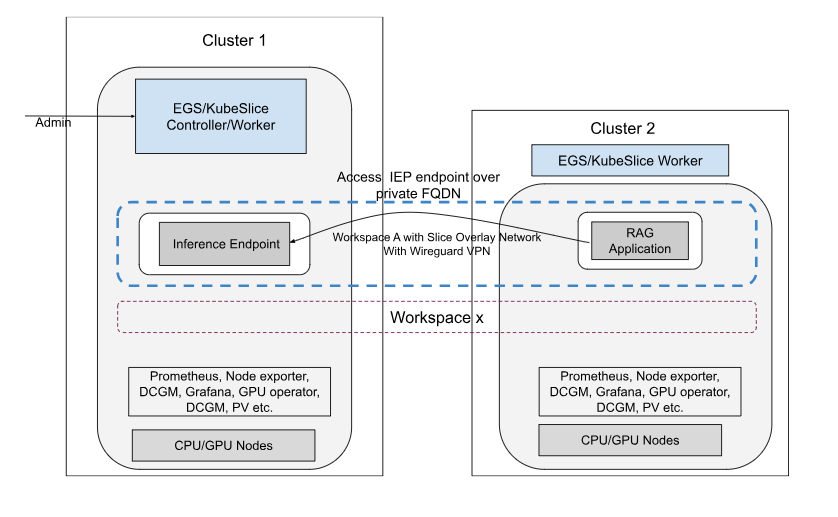
In this architecture, the workspace overlay network enables secure and efficient communication between workloads across multiple clusters. The overlay network is built using WireGuard, a modern VPN protocol with strong security features. Clusters connected to the workspace can communicate with each other over the WireGuard overlay network.
The key features of this architecture include:
- Cluster 1 hosts the EGS controller, EGS Worker, and an inference endpoint.
- Cluster 2 hosts EGS Worker and a RAG application.
- Both clusters are part of the same workspace, which provides isolation, multi-tenancy, and policy enforcement.
- A WireGuard-secured overlay network connects workloads across clusters, allowing the RAG Application to access the Inference Endpoint through a private FQDN.
- Monitoring and GPU management (Prometheus, DCGM, Grafana, GPU Operator, DCSM) are available in both clusters for unified observability.
Single Cluster Deployment
The following figure shows the topology of the EGS deployment on a single cluster.
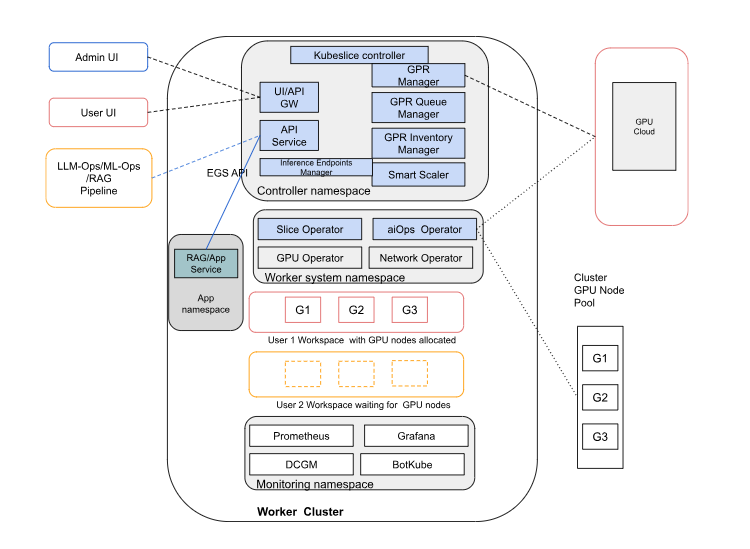
In a single-cluster deployment, controller, worker, monitoring, and GPU resources all run within one Kubernetes cluster. GPU nodes from the cluster pool are dynamically allocated to user workspaces through EGS APIs.
EGS Core LLM Deployments
The following figure shows the EGS Core APIs/SDK architecture for LLM use cases such as fine-tuning (FT) and inference through manual or pipeline deployments.
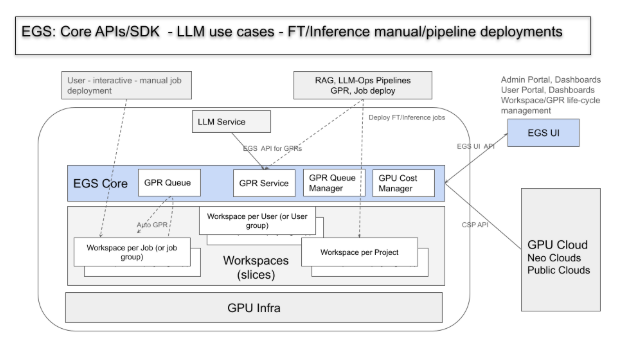
This architecture enables flexible deployment of LLM fine-tuning and inference workloads, either manually or via pipelines, across shared GPU infrastructure, while ensuring workspace isolation, GPU request management, cost tracking, and external cloud integration.
EGS with Dedicated Tenant Clusters
The following figure shows the EGS architecture with dedicated tenant clusters.
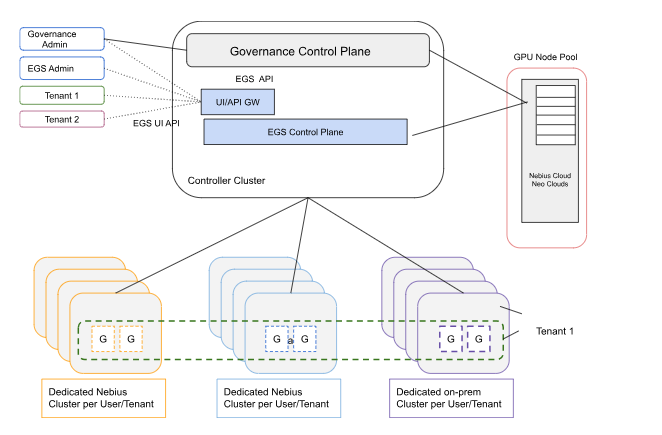
This architecture allows for dedicated clusters per tenant, providing isolation and dedicated resources for each tenant's workloads.
EGS Stack Reference Model
The following figure shows how AI/ML/LLM workloads are managed across infrastructure, provisioning, inference, and user-facing layers.
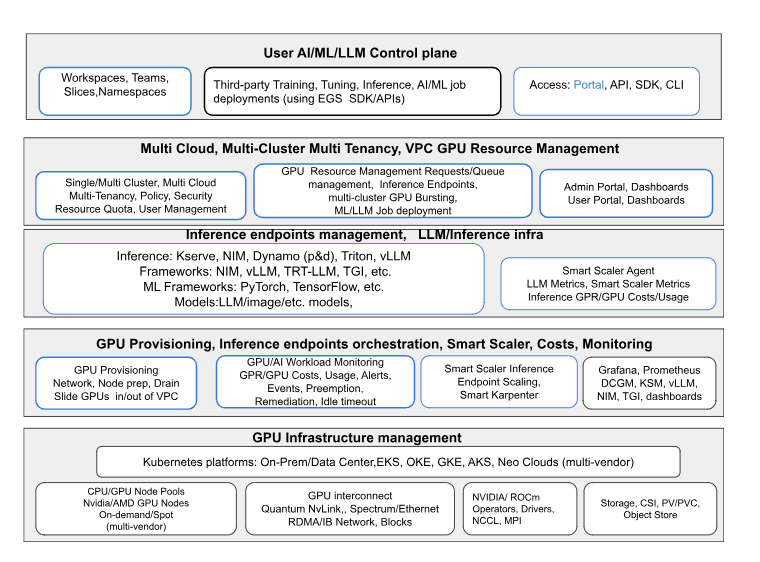
The EGS tech stack reference model provides an end-to-end framework for managing AI/ML/LLM workloads. It spans from GPU infrastructure and provisioning to inference orchestration, scaling, cost monitoring, and multi-cloud resource management. At the top, a unified control plane enables users to access workspaces, deploy jobs, and integrate with third-party tools through APIs, SDKs, or portals.