Manage Inference Endpoints
An Inference Endpoint is a hosted service to perform inference tasks such as making predictions or generating outputs using a pre-trained AI model. It enables real-time or batch processing for AI tasks like natural language processing and speech recognition. An Inference Endpoint serves as the operational interface to deploy AI models to users or applications.
This topic delves with managing Inference Endpoints on the EGS platform. An admin can create and manage multiple Inference Endpoints.
Across our documentation, we refer to the workspace as the slice workspace. The two terms are used interchangeably.
View Inference Endpoints
-
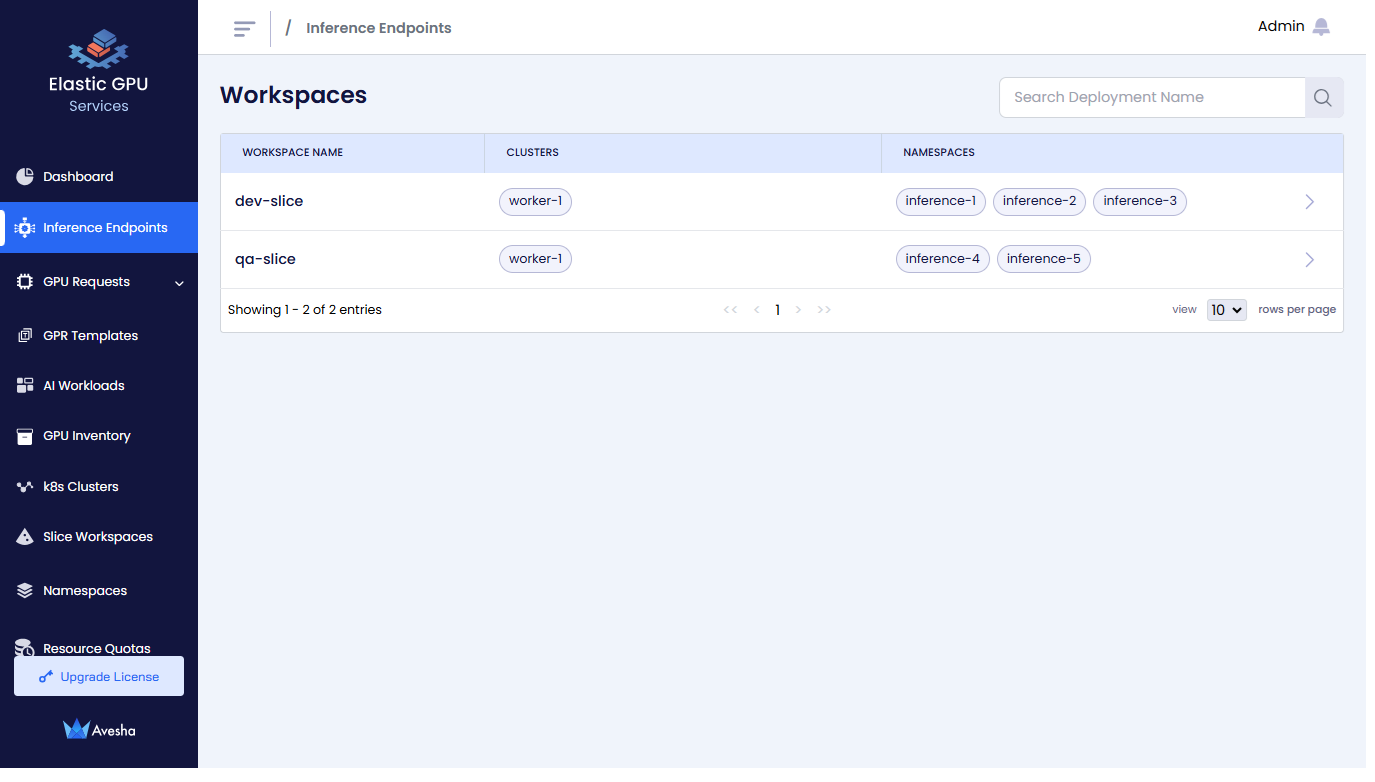
Go to Inference Endpoints on the left sidebar.
-
On the Workspaces page, click a workspace whose Inference Endpoints you want to view.
-
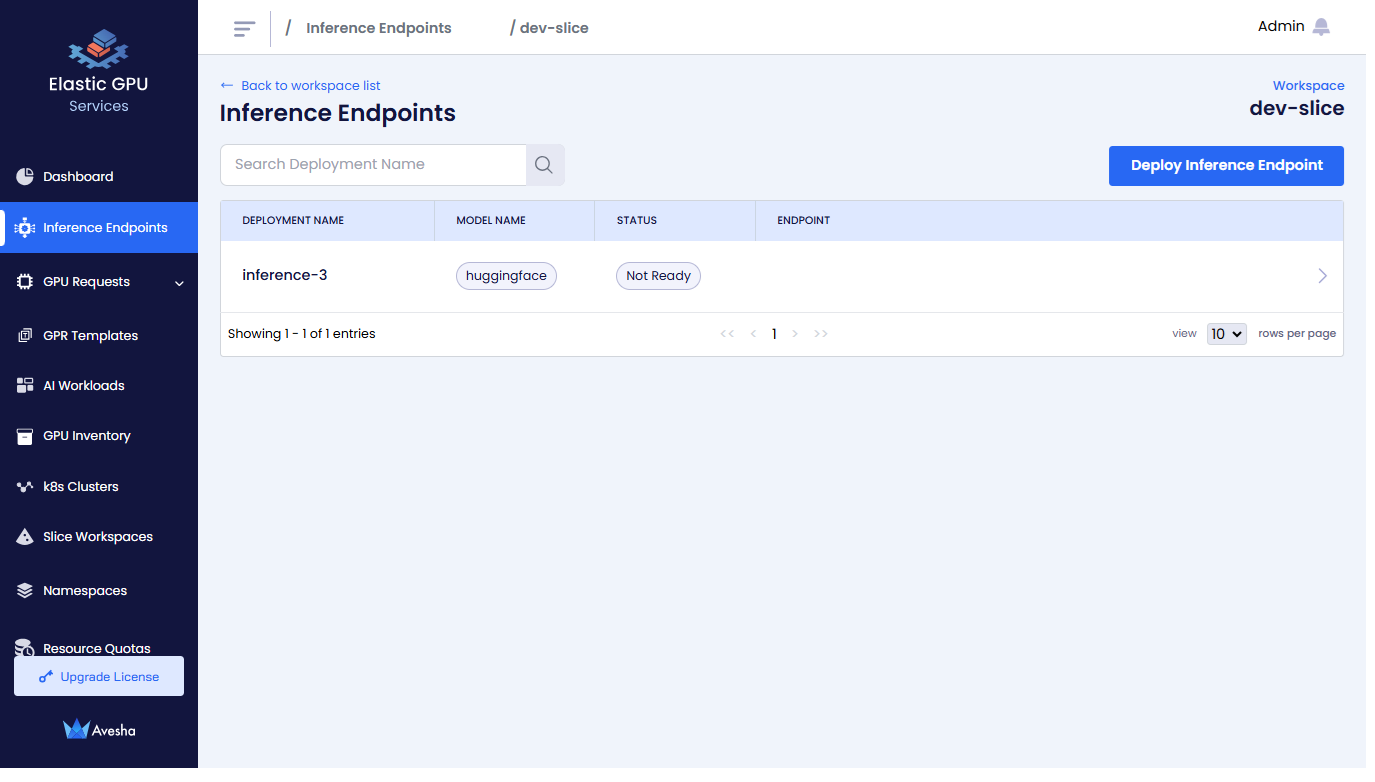
On the Inference Endpoints page, you see a list of Inference Endpoints for that workspace.
-
Click the
>icon for the Inference Endpoint that you want to view.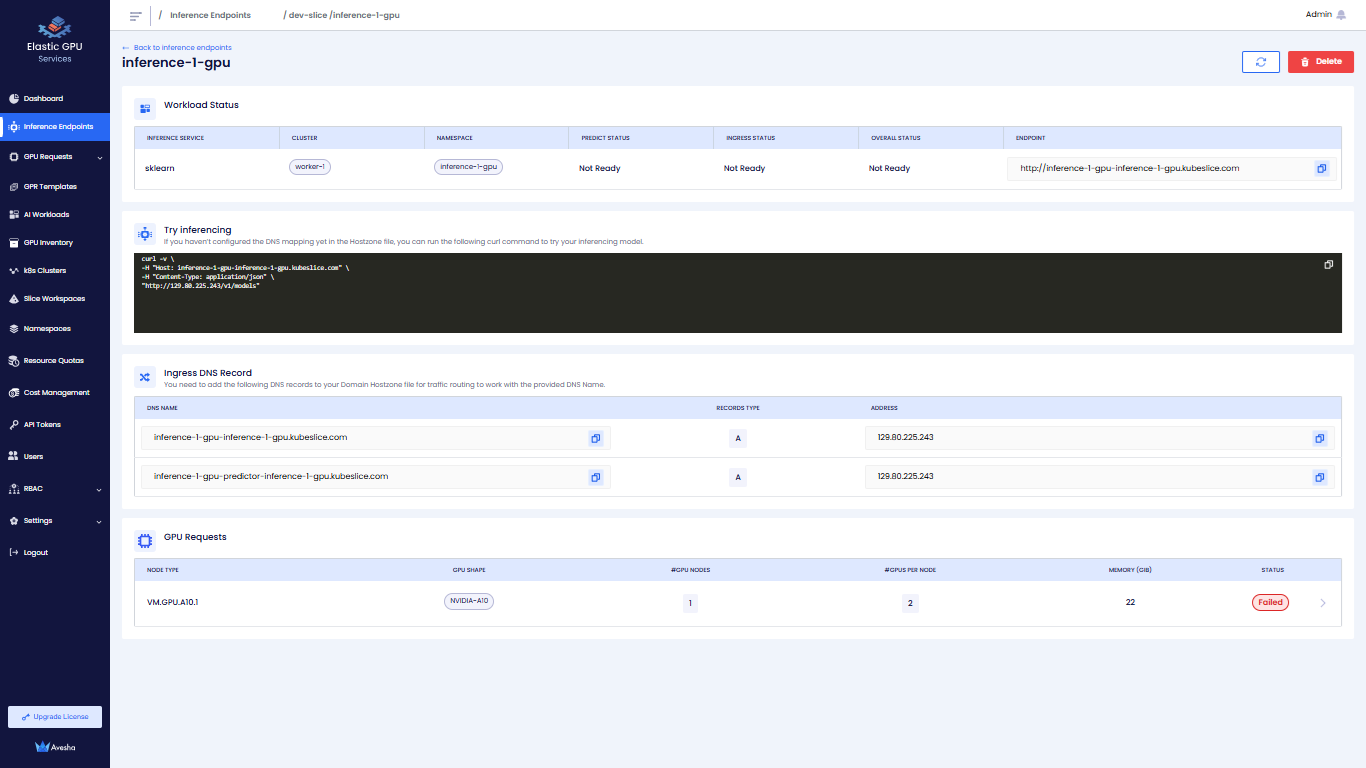
Deploy an Inference Endpoint
-
Go to Inference Endpoint on the left sidebar.
-
On the Workspaces page, go to the workspace on which you want to deploy an Inference Endpoint.
-
On the Inference Endpoints page, click Deploy Inference Endpoint.
-
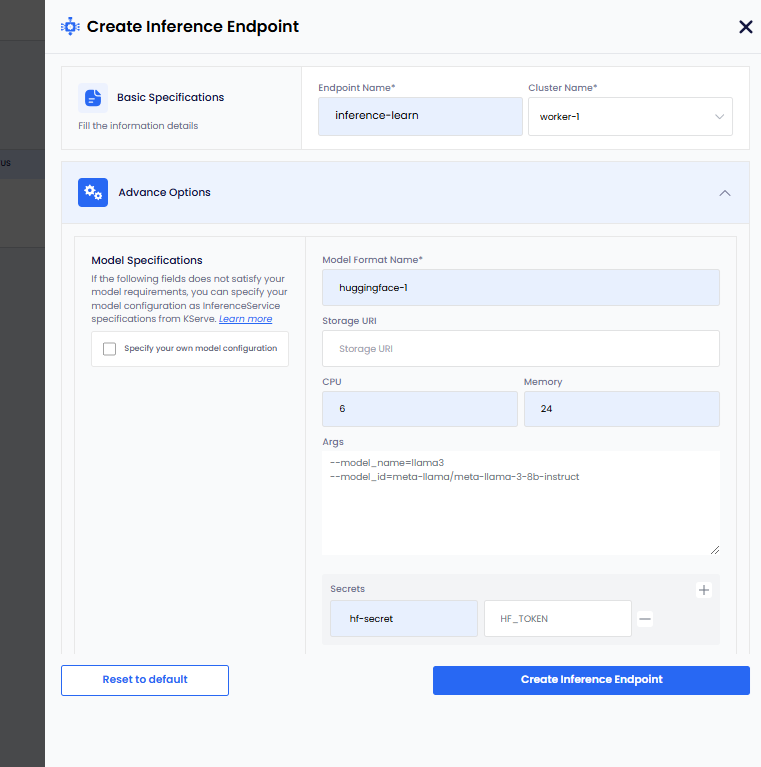
On the Create Inference Endpoint pane, under Basic Specifications:
- Enter a name for the Inference Endpoint in the Endpoint Name text box.
- From the Cluster Name, drop-down list, select the worker cluster on which you want to deploy this Inference Endpoint.
-
Under Advanced Options, for Model Specifications:
infoThe following parameters are standard and work for most models. However, if these parameters do not meet your model requirements, then select the Specify your own model configuration checkbox. To know more, see own model configuration.
- Enter a name in the Model Format Name text box.
- Add the storage URI in the Storage URI text box.
- Add the CPU value in the CPU text box.
- Add the Memory value in the Memory text box.
- Add the arguments in the Args text box.
- To add secret key-value pair, click the plus sign against Secret and add them.
Own Model Configuration
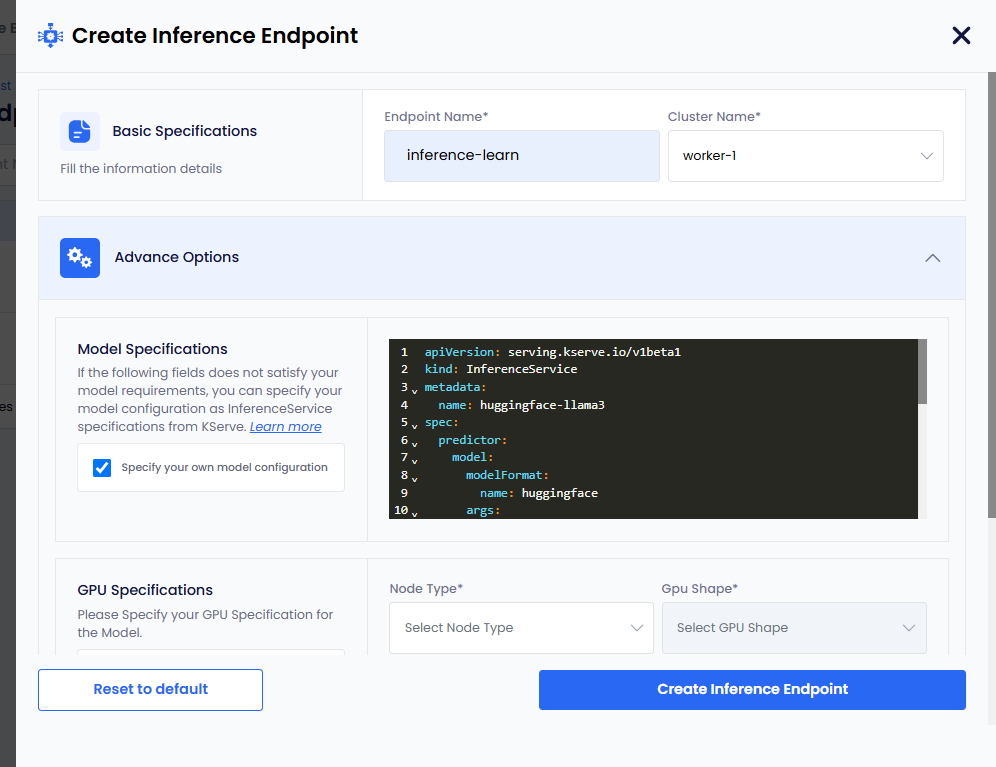
When the parameters provided under Model Specifications do not meet your model requirements, you can select the Specify your own model configuration checkbox.
To add your own model configuration:
-
Select the Specify your own model configuration checkbox, which provides you a terminal screen.
-
On the terminal screen, specify your model configuration as InferenceService specifications from KServe. For more information, see KServe.
-
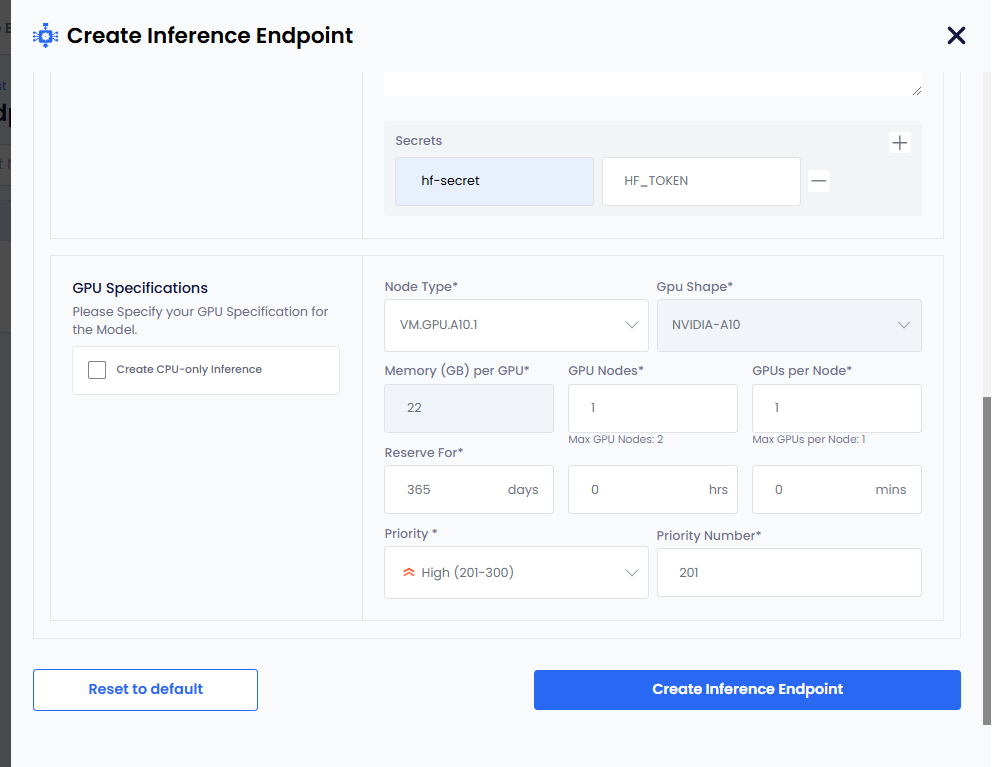
Under GPU Specifications:
infoIf you only want CPU-based inference, then select the Create CPU-only Inference checkbox.
-
Select node type from the Node Type drop-down list.
-
GPU Shape and Memory per GPU get auto populated.
-
The parameters, GPU Nodes and GPUs Per Node have default values. Change them if you want non-default values.
-
The Reserve For duration parameter in DDHHMM contains default value of 365 days.
infoThe maximum duration is 365 days. Change the duration to less than 365 days.
-
The Priority parameter has a default value. Select a different priority (low: 1-100, medium: 101-200, high: 201-300) from the drop-down list.
-
Set a different priority number as per the priority set. This parameter also contains a default value as per the default priority.
-
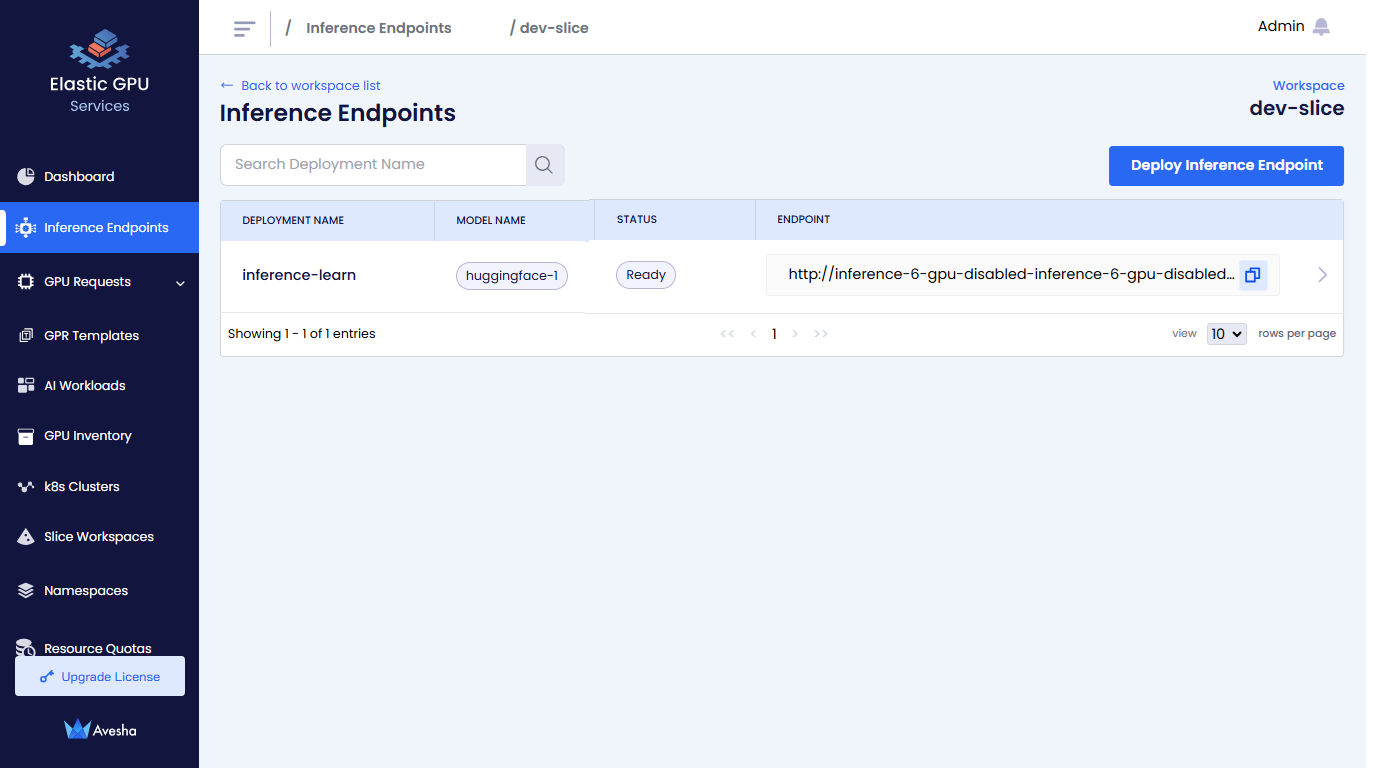
Click Create Inference Endpoint. The status goes to Pending before it changes to Ready.
-
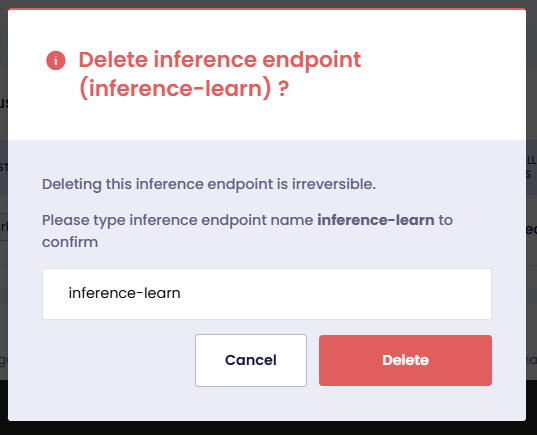
Delete an Inference Endpoint
-
On the Workspaces page, click a workspace whose Inference Endpoint you want to delete.
-
On that Inference Endpoints page, click the Delete button that is on the top-right corner.
-
On the confirmation dialog, type the name of the Inference Endpoint and click Delete.